What is the Heart disease prediction dataset about? It is a subset of variables from a study carried out in 1988 in different regions of the world to predict the risk of suffering a heart-related disease.
Note: In this readme only the results will be shown, for more details see the code in the code folder of this repo.
Why do we use this algorithm?
Because in machine learning it is normal to find problems where we have a huge amount of features where there are complex relationships between them and with the variable we want to predict.
Where can a PCA algorithm be used?
- Our dataset has a high number of features and not all of them are significant.
- There is a high correlation between the features.
- When there is overfitting.
- When it involves a high computational cost.
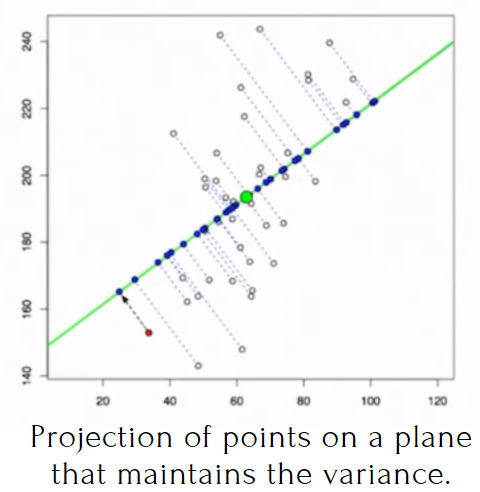
What is the PCA algorithm?
It basically consists of reducing the complexity of the problem:
1.- Selecting only the relevant variables.
2.- Combining them in new variables that keep the most important information (variance of the features).
Well, now that we have the context of our dataset, let's see what the result / precision was applying a logistic regression with the complexity reduction applied:
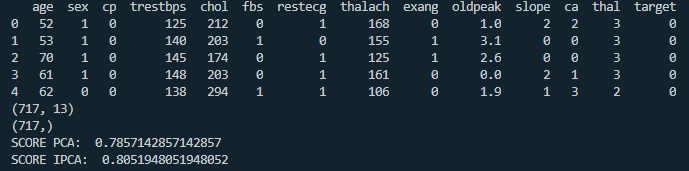
Well from the outset we see that the 2 algorithms have almost the same performance, but what do we achieve with this?
The original dataset had 13 features to try to predict a binary classification of whether the patient has heart disease or not, and now with PCA we only need 3 artificial features to arrive at a good enough result.
Conclusion: we are saving computational cost, since we are only using the relevant information for our model.
Now that we know the PCA algorithm, what other alternatives do we have?
Well, an alternative is the kernels. A kernel is a mathematical function that takes measurements that behave non-linearly and projects them into a larger dimensional space where they are linearly separable.
And what is this for?
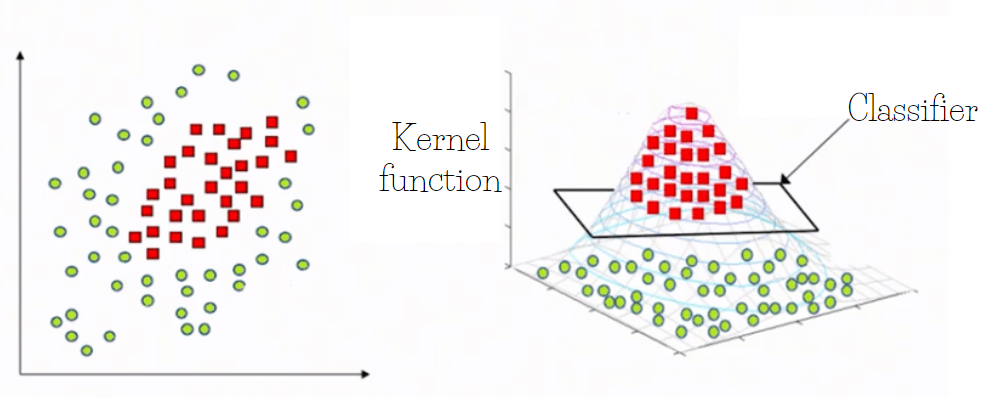
It serves for cases where they are not linearly separable. In the first image it is not possible to separate them with a line and in image 2 if we can do it through Kernels. What the Kernels function does is project the points into another dimension and thus make the data linearly separable.
Now we are going to implement kernels to our dataset and measure with which precession it was correct when classifying:

Conclusion: Implementing a kernel is relatively easy and has good precision, the biggest problem we will face is identifying when we will need to model a higher dimensional space.
What if instead of relying on the opinion of a single "expert" we consult the opinion of several experts in parallel and try to reach a consensus?
For this we have to imagine that our ML model is an expert, but what if we could have the opinion of several experts? Well, it would be much better, right? So, in this algorithm, several expert votes are taken into consideration and for this a count can be made or simply an average.
- It means to propel / propel.
- It is a sequential method.
- Seeks to gradually strengthen a learning model always using the residual error of the previous stages.
- The final result is also achieved by consensus among all models.
Now, we are going to see the results implementing the methods in code.
Here we can see the precession that all assembly methods had in relation to the KNN without assembly method:
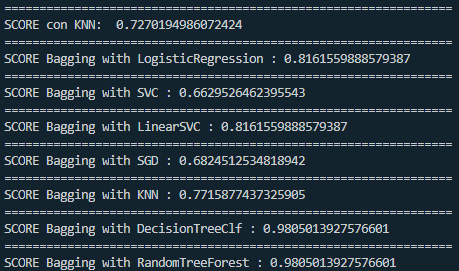
And finally the boosting precision:

As we can see, the Boosting method gave us very significant accuracy.
With the assembly methods, even though we had a classifier that was not that good, we can achieve much better results using the assembly methods. Also, a classifier alone is not always as powerful as applying that classifier many times with different parameters and different settings with a consensus method applied.
Conclusion: In a real life exercise we are classifying a patient and we have a super high percentage of accuracy when predicting a patient, so this is excellent support for a doctor in a clinic at work daily.
Data source: Heart Disease UCI
Although the code is not proprietary and is free to use, the data is licensed, please read it before using this data. This project is not for commercial purposes, it is for academic purposes only.